

The AEM platform starting from AEM 6 is based on a Jackrabbit OAK repository (replacing the Jackrabbit 2.X repository of previous versions). This repository can be split in two different storage elements: the Node Store and the Data Store (also called Blob Store).
Node store contains all the metadata and references of all information in the repository, whereas data store contains all information bigger than a predefined size (this size is configurable; standard is 4KB). So all data that are bigger than this size, will be stored on the data store and not in node store.
For example: it usually contains images, assets, and other binary data.
As you can imagine, one thing to take into account is that the data store may grow a lot, having even terabytes of data for a big site. This means that if we have an author instance and several publish instance, we need to store this big amount of data for each server.
In order to solve this issue, we can use the shared data store approach. This approach consists on having a unique data store, which is shared between the publish instances and eventually also with the author instance (in this case every file should have a flag saying if it’s published or not).
The schema can be seen in the following image:
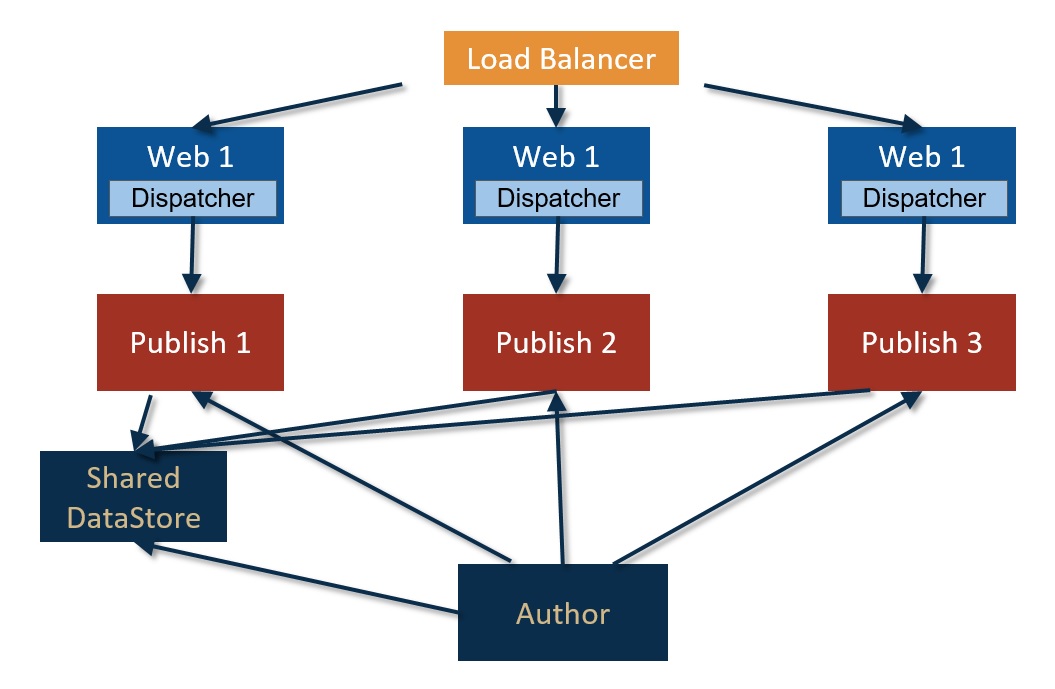
In this way we have only one data store, with the correspondent saving of space on disk. Another advantage is that the replication process can be faster, since once we publish a page, we don’t have to replicate also the binary data.
On the other hand, we need to take into account that maintenance of this approach will become more complex, having to pay attention to the shared nature of the data when we run the garbage collector process, in order to don’t remove active content.
How to configure Shared Data Store:
– Create the data store configuration file on each instances that is required to share the data store. On each configuration file, we need to point to the same data store.
– You can validate the configuration, looking for a unique file added to the data store by each repository that is sharing it with format repository-[UUID], where the UUID is a unique identifier of each individual repository.
– Also we can change the “Serialization Type” of the “Publish” replication agent from “Default” to “Binary Less” and add an additional argument (binaryless=true) to the replication agent’s “Transport URI”, meaning that the binary itself does not have to be transported across the network, resulting in a faster replication.


