

AEM content repository is based on Apache OAK, which implements the JCR standard. OAK allows to plug different indexers into the repository.
An indexer is a mechanism to optimize the searches on specific paths/node types/properties through the use of a structured data called index.
The advanced features in search are available only using fulltext seach indexes.
Only Lucene and Solr frameworks support indexes for fulltext search. Let’s consider Lucene.
Introducing Lucene
Lucene is a high-performance, scalable information retrieval (IR) library. IR refers to the process of searching for documents, information within documents, or metadata about documents. Lucene lets you add searching capabilities to your applications. It’s a mature, free, open source project implemented in Java.
It concerns the both indexing and searching phases:
- indexing: the document is acquired and transformed into a structured data optimized for searching;
- searching: the act to retrieve information based on the indexing output.
Indexing
To search large amounts of text quickly, you must first index that text and convert it into a format that will let you search it rapidly, eliminating the slow sequential scanning process. This conversion process is called indexing, and its output is called an index.
Collecting informations
Lucene allow to make searchable various kind of data sources.
It manage by default plain texts.
Using some of its extensions (for example Tika), it can also extract informations from other kind of structured textual files such as HTML, PDF, Word documents.
Also images containing texts can be parsed and indexed.
It’s possible to connect Lucene with DB to search on tables.
Building documents
Once you have the raw content that needs to be indexed, you must translate the content into the units (usually called documents) managed by the search engine. The document typically consists of several distinct named fields with values, such as title, body, abstract, author, and url. You’ll have to carefully design how to divide the raw content into documents and fields as well as how to compute the value for each of those fields. Often the approach is obvious: one email message becomes one document, or one PDF file or web page is one document. In other cases, it’s not so simple.
When a search will be performed, the engine will search only in the fields of the documents (only those marked as searchable).
Let’s say we the HTML page contains the following logical fields:
- Title
- Abstract
- Short Description
- Long description
- Tables
- Images
We want only index the title and the abstract fields.
Lucene manage only two kind of object:
- Document: the entity containing one of more fields. In this case, the web page.
- Fields: the unit containing the text to search. In this case, the title and the abstract.
Boosting documents and fields
Another common part of building the document is to inject boosts to individual documents and fields that are deemed more or less important. Perhaps you’d like your press releases to come out ahead of all other documents, all things being equal? Perhaps recently modified documents are more important than older documents?
Boosting may be done statically (per document and field) at indexing time or dynamically during searching. Nearly all search engines, including Lucene, automatically statically boost fields that are shorter over fields that are longer.
Analyzing documents
Analysis, in Lucene, is the process of converting field text into its most fundamental indexed representation, terms. These terms are used to determine what documents match a query during searching.
An analyser tokenizes text by performing any number of operations on it, which could include extracting words, discarding punctuation, removing accents from characters, lowercasing (also called normalizing), removing common words, reducing words to a root form (stemming), or changing words into the basic form (lemmatization).
This process is also called tokenization, and the chunks of text pulled from a stream of text are called tokens. Tokens, combined with their associated field name, are terms.
In Lucene, an analyser is a java class that implements a specific analysis.
Choosing the right analyzer is a crucial development decision with Lucene, and one size definitely doesn’t fit all. Language is one factor, because each has its own unique features. Another factor to consider is the domain of the text being analyzed; different industries have different terminology, acronyms, and abbreviations that may deserve attention. No single analyzer will suffice for all situations.
It’s possible that none of the built-in analysis options are adequate for your needs, and you’ll have to invest in creating a custom analysis solution, that means create a custom java class.
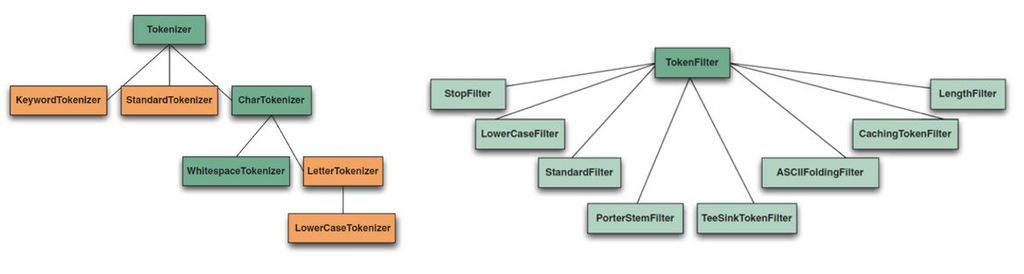
Analysis occurs any time text needs to be converted into terms, which in Lucene’s core is at two spots: during indexing and when searching. An analyzer chain starts with a Tokenizer, to produce initial tokens from the characters read from a Reader, then modifies the tokens with any number of chained TokenFilters.
An analyzer chain starts with a Tokenizer, to produce initial tokens from the characters read from a Reader, then modifies the tokens with any number of chained TokenFilters.
There are all sorts of interesting questions here:
- How do you handle compound words?
- Should you apply spell correction (if your content itself has typos)?
- Should you inject synonyms inlined with your original tokens, so that a search for “laptop”also returns products mentioning “notebook”?
- Should you collapse singular and plural forms to the same token? Often a stemmer is used to derive roots from words (for example, runs, running, and run, all map to the base form run).
- Should you preserve or destroy differences in case (lowercasing)?
- For non-Latin languages, how can you even determine what a “word” is?
All these features can by handled by one or more tokenizers or token filters.
Let’s see the most important built-in analyser available in Lucene bundle:
- WhitespaceAnalyzer, as the name implies, splits text into tokens on whitespace characters and makes no other effort to normalize the tokens. It doesn’t lowercase each token.
- SimpleAnalyzer first splits tokens at nonletter characters, then lowercases each token. Be careful! This analyzer quietly discards numeric characters but keeps all other characters.
- StopAnalyzer is the same as SimpleAnalyzer, except it removes common words. By default, it removes common words specific to the English language (the, a, etc.), though you can pass in your own set.
- KeywordAnalyzer treats entire text as a single token.
- StandardAnalyzer is Lucene’s most sophisticated core analyzer. It has quite a bit of logic to identify certain kinds of tokens, such as company names, email addresses, and hostnames. It also lowercases each token and removes stop words and punctuation.
The list below is an example for the stop words in English language"a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such","that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"
Let’s see an example of applying these analyzers:
| Analyzing: | “The email of XY&Z Corporation : xyz@example.com” |
| WhitespaceAnalyzer: | [The] [email] [of] [XY&Z] [Corporation] [:] [xyz@example.com] |
| SimpleAnalyzer: | [the] [email] [of] [xy] [z] [corporation] [xyz] [example] [com] |
| StopAnalyzer: | [email] [xy] [z] [corporation] [xyz] [example] [com] |
| KeywordAnalyzer: | [The email of XY&Z Corporation : xyz@example.com] |
| StandardAnalyzer: | [email] [xy&z] [corporation] [xyz@example.com] |
It’s important to notice that an analyzer is applied to a field, not to a document.
So if a document is composed by 4 fields, the analyzer is applied to each field separately.
Indexing documents
During the indexing step, the document is added to the index.
You can think of an index as a data structure that allows fast random access to words stored inside it.
The concept behind it is analogous to an index at the end of a book, which lets you quickly locate pages that discuss certain topics. In the case of Lucene, an index is a specially designed data structure, typically stored on the file system as a set of index files.
Searching
Searching is the process of looking up words in an index to find documents where they appear.
The quality of a search is typically described using precision and recall metrics:
- recall measures how well the search system finds relevant documents.
- precision measures how well the system filters out the irrelevant documents.
Search user interface
Lucene doesn’t provide a user interface, that is up to the specific application. But it provides functionalities that affect search results and how can be rendered:
- spellchecker for spell correction.
- excerpts extraction with hit highlighting.
- ranking order.
- pagination.
- refining results.
- find similar
Building queries
When you manage to entice a user to use your search application, she or he issues a search request, often as the result of an HTML form or Ajax request submitted by a browser to your server. You must then translate the request into the search engine’s Query object.
The query may contain Boolean operations, phrase queries (in double quotes), or wildcard terms.
Many applications will at this point also modify the search query so as to boost or filter for important things (for example, an e-commerce site will boost categories of products that are more profitable, or filter out products presently out of stock).
Searching queries
Search Query is the process of consulting the search index and retrieving the documents matching the Query, sorted in the requested sort order. This component covers the complex inner workings of the search engine, and Lucene handles all of it for you.
Building index
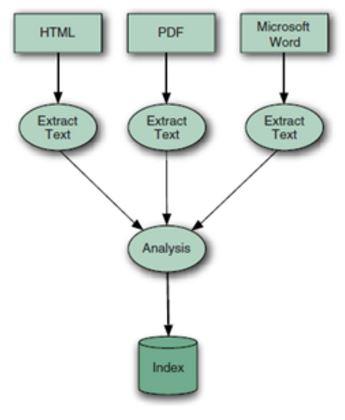
During indexing, the text is first extracted from the original content and used to create an instance of Document, containing Field instances to hold the content.
The text in the fields is then analyzed to produce a stream of tokens, optionally applying a number of operations on them.
For instance, the tokens could be lowercased before indexing, to make searches case insensitive, using Lucene’s LowerCaseFilter. Typically it’s also desirable to remove all stop words, which are frequent but meaningless tokens, from the input (for example a, an, the, in, on, and so on, in English text) using StopFilter. Similarly, it’s common to process input tokens to reduce them to their roots, for example by using PorterStemFilter for English text (similar classes exist in Lucene’s contrib analysis module, for other languages).
The combination of an original source of tokens, followed by the series of filters that modify the tokens produced by that source, make up the analyzer. You are also free to build your own analyzer by chaining together Lucene’s token sources and filters, or your own, in customized ways. Finally, those tokens are added to the index in a segmented architecture.
Searching with stemming and synonyms in AEM
Definitions
Let’s understand what stemming and synonyms are before see how to handle them in AEM.
Stemming
The stemming is process to reduce a word in its root/base form or in its lemma (lemmatisation).
| Word | Base form / lemma |
| books | book (base form) |
| booking | book (base form) |
| fishing | fish (base form) |
| fished | fish (base form) |
| fisher | fish (base form) |
| am | be (lemma) |
| was | be (lemma) |
Searching with stemming means that if I search for the word fishing, I want include in the results the matching for all words whose base form is fish: fish, fished, fishing, fisher, etc..
Synonyms
The synonyms are two or more words with the same or nearly the same meaning.
Examples:
- intelligent, smart, bright, brilliant, sharp
- old, antiquated, ancient, obsolete, extinct, past, prehistoric, aged
- true, genuine, reliable, factual, accurate, precise, correct, valid, real
- important, required, substantial, vital, essential, primary, significant, requisite, critical
Searching with synonyms means that if I search for the word intelligent, I want include in the results also all its synonyms: smart, bright, brilliant, sharp, etc..
Configuring analyzers in AEM
As we could see in the previous chapters, the advanced search features are managed in AEM configuring Lucene indexes.
Indexes are store in the repository at path /oak:index.
Analyzers can be configured as part of index definition via analyzers node.
The default analyzer can be configured via analyzers/default node
/oak:index/indexName - jcr:primaryType = "oak:QueryIndexDefinition" - compatVersion = 2 - type = "lucene“ - async = "async" + analyzers + default +...
Current only one analyzer is supported for each index, so you’re forced to configure the default node if you want to add an analyzer to an index.
Two alternative configurations
- By specifying the java class implementing the analyzer
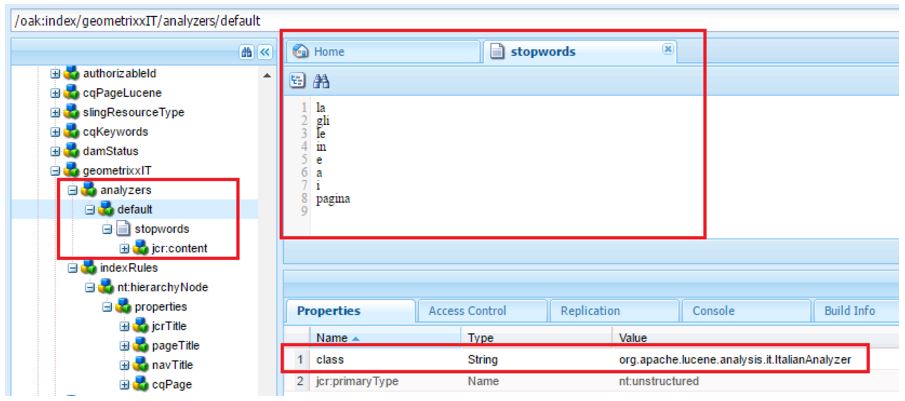
- By composition: listing the tokenizers and token filters that implement the analyzer.
Name of tokenizers and token filters are specified by removing the factory suffixes in the Java class name.
For instance:
- org.apache.lucene.analysis.standard.StandardTokenizerFactory -> Standard
- org.apache.lucene.analysis.charfilter.MappingCharFilterFactory -> Mapping
- org.apache.lucene.analysis.core.StopFilterFactory -> Stop
Any config parameter required for the factory is specified as property of that node.
If the factory requires to load a file e.g. stop words from some file then file content can be provided via creating child nt:file node of the filename.
ATTENTION: the order in which filters are in the repository is the same of that followed in the processing chain of the analyzer!
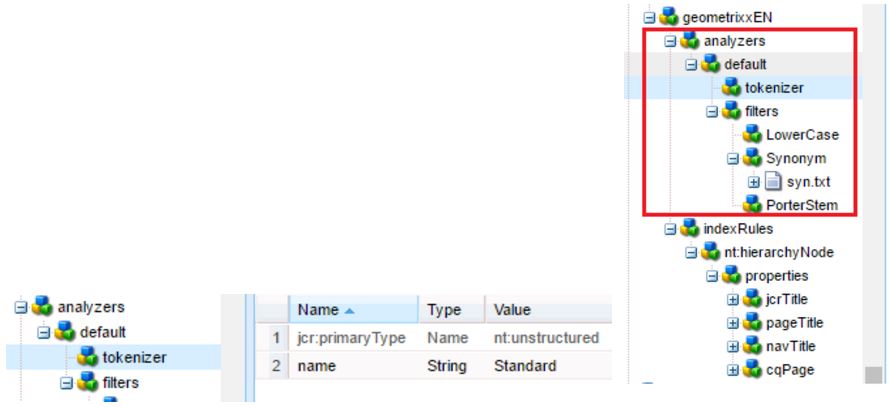
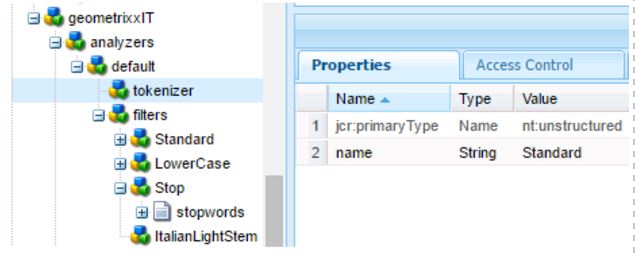
Stemming in AEM
For English language, the Porter stemming algorithm is the most common.
So, by composition, it’s enough to specify the create the node PorterStem under the filters node (see image above).
For other languages, Lucene includes one analyzers for each language including common features and the stemming one.
So it’s possibile specify by Java class the analyzer according to the chosen language:
ArabicAnalyzer, ArmenianAnalyzer, BasqueAnalyzer, BrazilianAnalyzer, BulgarianAnalyzer, CatalanAnalyzer, CJKAnalyzer, CzechAnalyzer, DanishAnalyzer, EnglishAnalyzer, FinnishAnalyzer, FrenchAnalyzer, GalicianAnalyzer,GermanAnalyzer, GreekAnalyzer, HindiAnalyzer, HungarianAnalyzer, IndonesianAnalyzer, IrishAnalyzer, ItalianAnalyzer, LatvianAnalyzer, NorwegianAnalyzer, PersianAnalyzer, PortugueseAnalyzer, RomanianAnalyzer, RussianAnalyzer, SoraniAnalyzer, SpanishAnalyzer, SwedishAnalyzer, ThaiAnalyzer, TurkishAnalyzer
See Lucene API for canonical Java class names and futher informations.
If you want implement it by composition, I suggest to take a look at the code of language specific analyzer to extract the token filters chain.

Synonyms in AEM
The implementation of synonyms is only possible by composition, using the SynonymFilterFactory class.
The synonyms dictionary is configured as parameter of the Synonyms node.
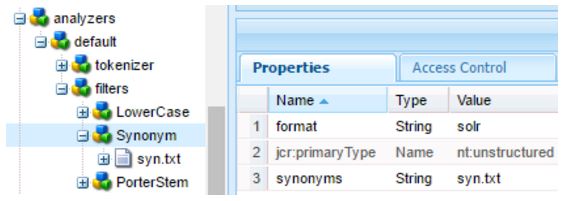
There are two possible formats for the dictionary:
- wordnet: based on the popular Wordnet community which has a project for multilanguage dictionary. The format is a little bit complex. Example: [IMAGE9]
- solr: it’s more plain text similar. Example: second, 2nd, two
Autocompletion and Suggestion
When you start to write something in a search form, nowadays what happens more often is that application start to help you with some useful feature like autocompletion or suggesting you some words to search and maybe also with some cool predictive search as Google likes to call that.
However this is a good chance to make some opinionated definitions with the help of the following images.
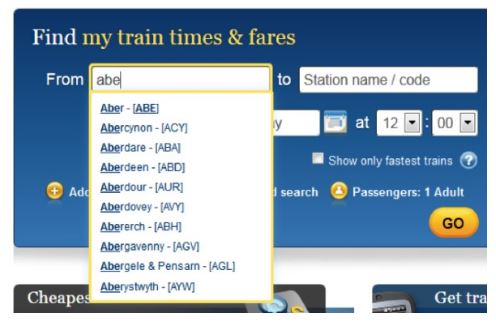
The purpose of auto-complete is to resolve a partial query, i.e., to search within a controlled vocabulary for items matching a given character string . Tipically can be used to complete the search of the user for a city or state in a booking transport application.
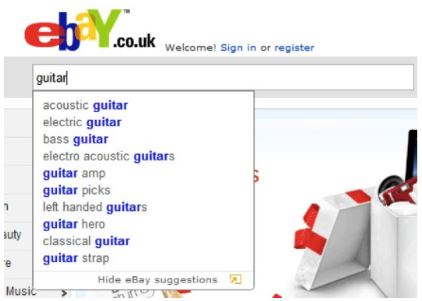
The purpose of auto-suggest is to search a virtually unbounded list for related keywords and phrases, which may or may not match the precise query string. What you receive with auto suggestion is just an advice for your search query. After select one of this suggestion you are redirect to a page with search results.
One step forward is to present directly the results while user is writing is query search . This is the most advanced feature but it also the one with most impacts in the performance application.
Starting from AEM 6.1 the feature of suggestion is available thank to the suggest module of Lucene.
This module provides a dedicated and optimized data structure allows the engine to give autocompletion and suggestion feature without indexing all the possibile n-grams of a word. There is a specific analyzer (AnalyzingInfixSuggester) used that loads the completion values from the indexed data and then build the optimized structure in memory for a fast lookup.
In the following image you can see an example of an optimized lookup data structure:
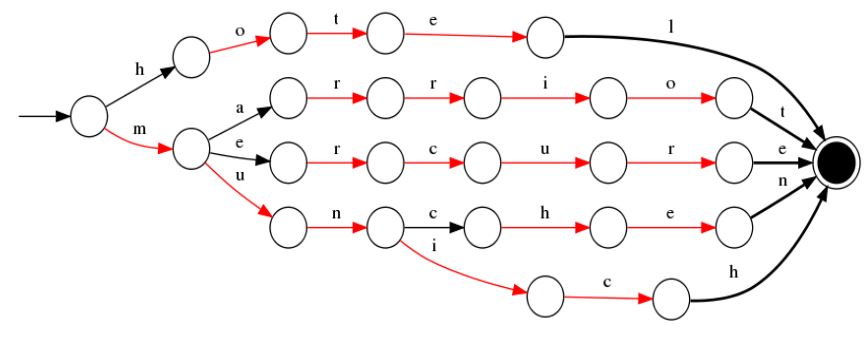
If a user start to write the char h this structure is immediately able to suggest hotel as this is the only available path for the indexed data.
In order to implements the autosuggestion feature you need to define an index of type Lucene and for each property X of nodes that you are indexing you can add a specific property useInSuggest to tell to the engine to use X for suggesting query to the user.
The following image shows a complete example definition of an index that use the property jcr:description of a node nt:base for the suggestion feature.
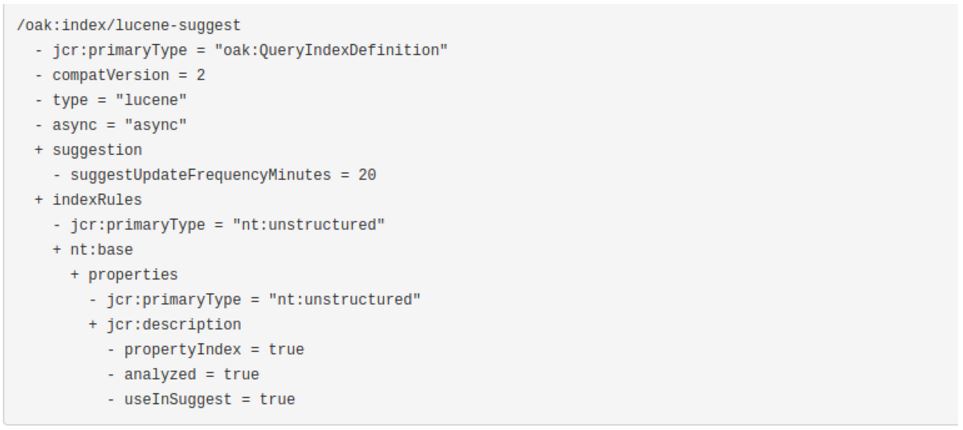
An additional property suggestUpdateFrequencyMinutes define the frequency of updating the indexed suggestions an can be useful to mitigate performance issues that can arise if indexed properties are frequently updated by the users of your application. The default value is 10 minutes.
If you want to use that autosuggestion feature in your application you need to write a specific query to retrieve the suggested terms. Keep following the same example you need to write:
SELECT [rep:suggest()] FROM nt:base WHERE SUGGEST('SEARCHINPUT')
where SEARCHINPUT is what the user write in your search form.
BIBLIOGRAPHY
Lucene in Action, 2nd edition by Michael McCandless, Erik Hatcher, Otis Gospodnetić. Manning Publications & co.
http://jackrabbit.apache.org/oak/docs/query/lucene.html
https://docs.adobe.com/docs/en/aem/6-2/deploy/platform/queries-and-indexing.html
https://lucene.apache.org/core/4_7_1/index.html
https://docs.adobe.com/content/ddc/en/gems/oak-lucene-indexes.html
http://www.aemstuff.com/blogs/feb/aemindexcheatsheat.html
AUTHORS
Aldo Caruso, Marco Re


