

In today’s digital landscape, visual search is transforming the way users engage with content. Developing AEM visual search engine requires a solution that is both robust and user-friendly, enabling users to search for content using either images or text queries. By leveraging semantic similarities, the system retrieves visually or contextually related images, enhancing the overall search experience beyond traditional text-based methods.
In this article, I’ll Walk you through the journey of developing this visual search in AEM, explaining the technologies behind it, the key components involved, and best practices to integrate image similarity and text-based semantic search within the AEM environment. Whether you’re looking to implement something similar or are just curious about how visual search works, this guide should provide you with a comprehensive understanding.
We’ll cover:
- How to implement a semantic search system using text and image embeddings.
- The role of cosine similarity in comparing embeddings.
- How to integrate this functionality within an AEM environment.
Technologies Used
- Flask: it was chosen because of its simplicity, flexibility, and lightweight nature, which makes it ideal for quickly building a web service that processes both text and image queries. Unlike more complex frameworks, Flask provides just the essentials, which means we could focus more on integrating the visual search capabilities rather than managing heavy infrastructure. Additionally, Flask’s compatibility with Python libraries, like Sentence-Transformers made it a natural choice for embedding generation and similarity computations.
- PostgreSQL (with pgvector): a powerful open-source database known for its reliability and scalability. We opted to store image embeddings in PostgreSQL due to its ability to handle large datasets efficiently and its compatibility with pgvector, an extension that allows storing and querying vector data.
- Sentence-Transformers is a Python library that makes it easy to generate dense vector representations (called embeddings) for both text and images. These embeddings capture the meaning of a query, allowing for more accurate searches. It uses models like CLIP, a model which was developed by OpenAI for the images and text embeddings. It’s open-source, with both the model and dataset available on Hugging Face.
Understanding Semantic Search
Semantic search goes beyond simple keyword matching by understanding the meaning and context behind the search query. This is achieved through embeddings, which are dense vector representations of text or images. Embeddings capture the semantic information of a query or document, allowing for more accurate matching.
Key Concepts
1. Embeddings: Embeddings are numerical representations of data (text or images) in a continuous vector space. For example, using Sentence-Transformers and CLIP , we can transform queries and documents into embeddings that can be compared with each other.
- Sentence-Transformers: is a Python library that provides an easy way to compute dense vector representations (also known as embeddings) for sentences, paragraphs, and images. These embeddings are typically used for tasks such as semantic search, clustering, and classification. The library is built on top of popular transformer-based models and provides a wide variety of pre-trained models optimized for different tasks.
This library is being used to load and utilize a pre-trained model called clip-ViT-B-32. The model’s primary function is to encode both text and images into dense vector embeddings, which can then be used to find similarities between them.
model = SentenceTransformer(‘clip-ViT-B-32’)
The SentenceTransformer is instantiated with the clip-ViT-B-32 model, which is a version of the CLIP (Contrastive Language-Image Pretraining) model. This model can encode both images and text, making it versatile for tasks that involve comparing images to images, text to text, or even text to images.
embedding = model.encode(text_query, normalize_embeddings=True)
In our case, The model is used to convert text queries and images into vector embeddings.
- CLIP: (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be instructed in natural language to predict the most relevant text snippet, given an image, The model uses a technique called contrastive learning, where it learns to distinguish between correct and incorrect image-text pairs. By learning these associations, CLIP can perform tasks such as image classification, image retrieval, and zero-shot learning without needing to be fine-tuned on specific tasks.
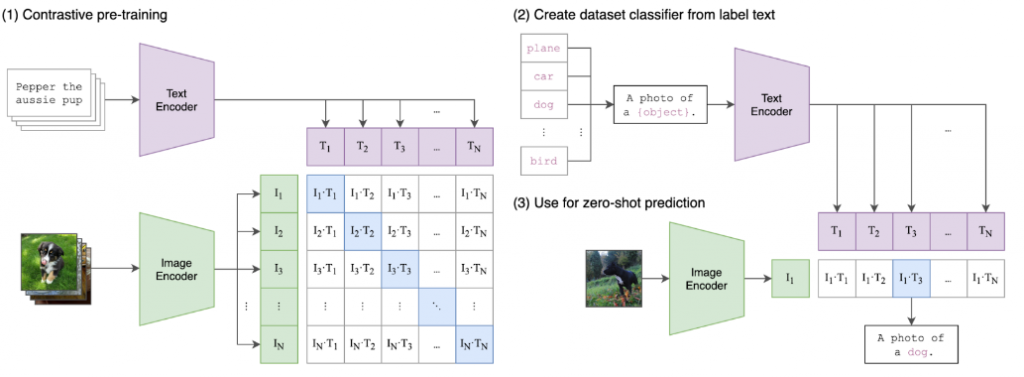
2. Cosine Similarity: Once we have the embeddings, the similarity between them can be measured using cosine similarity. Cosine similarity calculates the cosine of the angle between two vectors, providing a value between 0 and 1, or [-1, 1] where 1 indicates identical vectors. Then it was used to compare query embeddings (from text or images) with stored embeddings to find the most similar items.
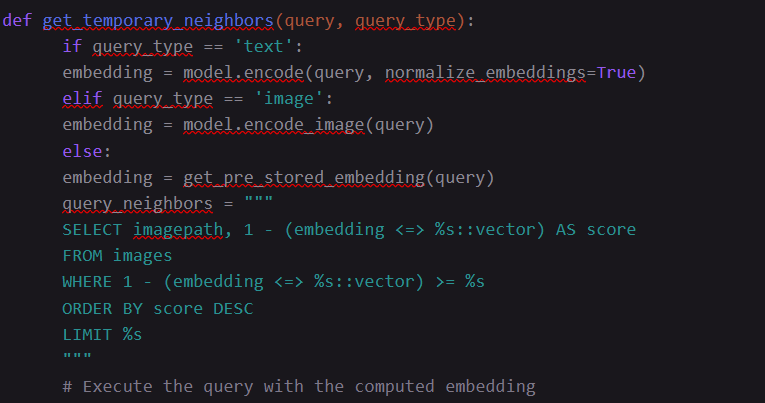
Example: query_neighbors = “”” SELECT imagepath, 1 – (embedding <=> %s::vector) AS score FROM images WHERE 1 – (embedding <=> %s::vector) >= %s ORDER BY embedding <=> %s::vector LIMIT %s “””
Note:
- embedding <=> %s::vector: Calculates cosine distance.
- 1 – (embedding <=> %s::vector) AS score: Converts distance to cosine similarity (1 = most similar).
- Query filters and orders results based on similarity scores, returning the most relevant matches.
Implementing the Search Solution
Now that we’ve explored the key technologies, we can build a Flask-based web service that handles both text and image queries, delivering a seamless search experience.
- Text Query: Direct text input from the user.
- Image Upload/Camera Capture Query: Images uploaded by the user or captured through a camera.
- Image Click Query: Clicking on an image to find similar ones.
Here is an example of how everything can come together.
Integrating with AEM
After developing our Flask-based web service, now we can integrate it with AEM to enhance the search experience:
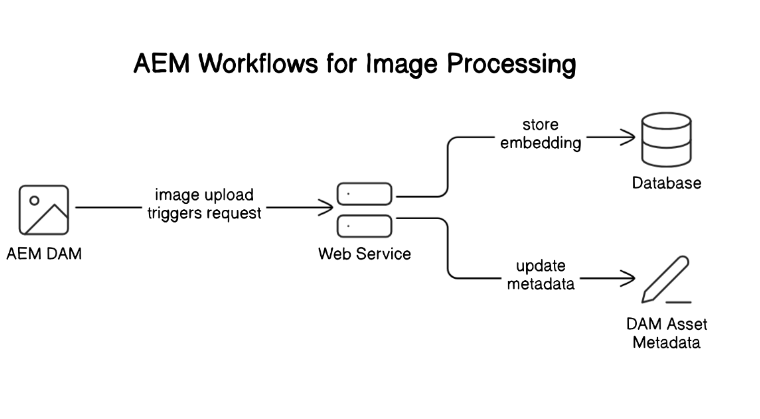
AEM Workflows for Image Processing
- Listening for Image Uploads: AEM workflows can be configured to trigger upon the upload of images to the DAM. When an image is uploaded, the workflow sends a request to our Flask web service, including the image path.
- Generating and Storing Embeddings: Upon receiving the request, the web service generates an embedding for the image. This embedding, along with the image path and a unique ID, is stored in a PostgreSQL database.
- Updating Image Metadata: Once the embedding is stored, the web service updates the image’s metadata in AEM with the vector_id (the unique ID from the database). This ID is later used to retrieve similar images when a user clicks on the image.
Now, we can provide end-user components for a seamless search experience.
- Visual Search Image Gallery: This component can allow users to interactive and dynamic browsing experience. Users can explore a curated list of images and, with a simple click, discover visually similar images.
- Visual Search Field: Users can search using text or images (uploaded or captured). This component sends the query to our web service and displays relevant search results based on the response.
References and Further Reading
- Sentence-Transformers Documentation
- CLIP: Contrastive Language–Image Pretraining
- Understanding Cosine Similarity
- Adobe Experience Manager Workflows
- Huggingface
Conclusion
By combining AEM’s capabilities with state-of-the-art semantic search techniques, we’ve created a powerful solution that enables both text and image-based search functionalities. This leverages machine learning models to understand and process queries, making it easier for users to find relevant content quickly and accurately.
Whether you’re working in e-commerce, digital media, or any other content-driven industry, integrating visual search into your platform can significantly enhance user experience and content discoverability.


